相关导航

pandas 数据透视
看过来
《pandas 教程》 持续更新中,提供建议、纠错、催更等加作者微信: gairuo123(备注:pandas教程)和关注公众号「盖若」ID: gairuo。跟作者学习,请进入 Python学习课程。欢迎关注作者出版的书籍:《深入浅出Pandas》 和 《Python之光》。

数据透视是最常用的数据汇总工具,Excel 中经常会做数据透视,它可以根据一个或者多个指定的维度来聚合数据。Pandas 也提供了数据透视函数来实现这些功能。
整理透视 pivot
可以看一下它的逻辑:

这里有三个参数,作用分别是:
- index:新 df 的索引列,用于分组,如果为None,则使用现有索引
- columns:新 df 的列,如果透视后有重复值会报错
- values:用于填充 df 的列。 如果未指定,将使用所有剩余的列,并且结果将具有按层次结构索引的列
整理透视案例
df = pd.DataFrame({'foo': ['one', 'one', 'one', 'two', 'two',
'two'],
'bar': ['A', 'B', 'C', 'A', 'B', 'C'],
'baz': [1, 2, 3, 4, 5, 6],
'zoo': ['x', 'y', 'z', 'q', 'w', 't']})
'''
foo bar baz zoo
0 one A 1 x
1 one B 2 y
2 one C 3 z
3 two A 4 q
4 two B 5 w
5 two C 6 t
'''
# 透视
df.pivot(index='foo', columns='bar', values='baz')
'''
bar A B C
foo
one 1 2 3
two 4 5 6
'''
# 多层索引,取其中一列
df.pivot(index='foo', columns='bar')['baz']
'''
bar A B C
foo
one 1 2 3
two 4 5 6
'''
# 指定值
df.pivot(index='foo', columns='bar', values=['baz', 'zoo'])
'''
baz zoo
bar A B C A B C
foo
one 1 2 3 x y z
two 4 5 6 q w t
'''
以下是《深入浅出Pandas》中的一个例子:
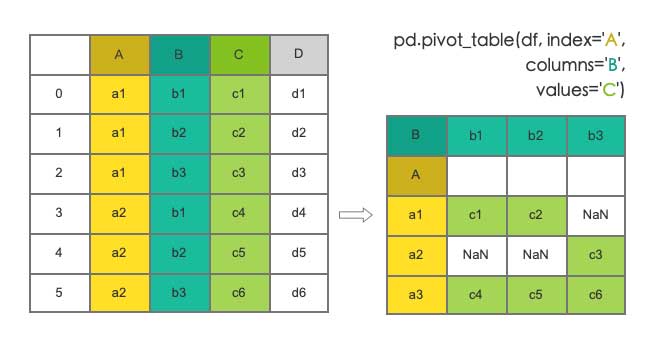
聚合透视 Pivot Table
df.pivot() 只能将数据进行整理,如果遇到重复值要进行聚合计算,就要用到pd.pivot_table()。它可以实现类似 Excel 那样的高级数据透视功能。

一些参数介绍:
- data: 要透视的 DataFrame 对象
- values: 要聚合的列或者多个列
- index: 在数据透视表索引上进行分组的键
- columns: 在数据透视表列上进行分组的键
- aggfunc: 用于聚合的函数, 默认是 numpy.mean
聚合透视案例
df = pd.DataFrame({"A": ["foo", "foo", "foo", "foo", "foo",
"bar", "bar", "bar", "bar"],
"B": ["one", "one", "one", "two", "two",
"one", "one", "two", "two"],
"C": ["small", "large", "large", "small",
"small", "large", "small", "small",
"large"],
"D": [1, 2, 2, 3, 3, 4, 5, 6, 7],
"E": [2, 4, 5, 5, 6, 6, 8, 9, 9]})
df
'''
A B C D E
0 foo one small 1 2
1 foo one large 2 4
2 foo one large 2 5
3 foo two small 3 5
4 foo two small 3 6
5 bar one large 4 6
6 bar one small 5 8
7 bar two small 6 9
8 bar two large 7 9
'''
将 D 列值加和,索引为 AB,列为 C 不去重值:
table = pd.pivot_table(df, values='D', index=['A', 'B'],
columns=['C'], aggfunc=np.sum)
table
'''
C large small
A B
bar one 4.0 5.0
two 7.0 6.0
foo one 4.0 1.0
two NaN 6.0
'''
空值的传入:
table = pd.pivot_table(df, values=['D', 'E'], index=['A', 'C'],
aggfunc={'D': np.mean,
'E': np.mean})
不同值使用不同的聚合计算方式:
table = pd.pivot_table(df, values=['D', 'E'], index=['A', 'C'],
aggfunc={'D': np.mean,
'E': [min, max, np.mean]})
汇总边际,给列的每层加一个 all 列进行汇总,计算方式与 aggfunc 相同。
pd.pivot_table(df, values='D', index=['A', 'B'],
columns=['C'], aggfunc=np.sum,
margins=True)
todo.
相关内容
- pandas 同组数据转为同一行 2023-03-30 18:59:26
- pandas 数据透视值用逗号拼接 2022-09-12 09:44:07
更新时间:2021-09-16 14:01:44 标签:pandas 透视
